Introduction
Several thousands of papers are being published everyday. A paper published about a decade ago wrote “the total number of science papers published since 1665 passed 50 million. About 2.5 million new scientific papers are published each year.” In the introduction section of one of my previous systematic review, I wrote “The number of published research doubles every 9 years and its growth particularly in medicine and health care is exponential.”
Doing systematic reviews on a certain topic requires an extensive database search, title/abstract screening, full-text screening, quality assessment, data extraction, qualitative, quantitative synthesis and other important steps. Of these steps, at least title/abstract screening and full text reviews is required to be done by two review authors.
Going through the title and abstract of thousands of papers is time-taking, and laborious. Yet, policy makers medical practitioners require the latest evidence for making urgent decisions. Thanks to the development of machine learning and artificial intelligence over the past decade, systematic reviews can be used to automate or semi-automate some of the steps of systematic reviews. Systematic reviewers are already using some web-based text mining and machine learning tools such as Abstrackr, Robotreviewer, RobotAnalyst, etc. However, it is worth a try to implement text classification algorithms in R.
In a paper “Why Should I Trust You?”: Explaining the Predictions of Any Classifier", Riberio TL et.al described machine learning models as mostly “black boxes”. The biggest challenge of machine learning is interpretability and applying it to local context or simply to an individual or observation with a specific characteristics. They developed LIME which was later changed into Python and R packages. Lime can help explain several models implemented in about six different packages including caret, h2o, and xgboost.
In this blog post, I want to try one of the many available methods available to check whether machine learning methods correctly discriminates SARS papers from COVID19 papers. I know the two viruses are highly related. I am only using the SARS and COVID for demonstrations.
Data
I used the covid19 data that I used in my previous blog post. In addition, I have added new reference data by searching SARS papers published from January 1/2003 until September 12/2003.
As I did in my last blog, I read my files using the beautiful bib2df package. You can also use bibliometrix or revtools packages to convert bibtex files to data frame in R. With revtools, you can also convert .ris files to data frame. Awesome!
# library(bib2df)
# library(dplyr)
#
# covid <- bib2df("covid19.bib") %>% # import references
# filter(!is.na(ABSTRACT)) %>% # select only papers with no missing abstract
# select("TITLE", "ABSTRACT", "KEYWORDS", "AUTHOR", "BIBTEXKEY") # Select few variables
#
#
# # 2003 corona virus
# covexclude <- bib2df("covexclude.bib") %>%
# filter(!is.na(ABSTRACT)) %>%
# select("TITLE", "ABSTRACT", "KEYWORDS", "AUTHOR", "BIBTEXKEY")
#
# cov2003 <- bib2df("cov2003.bib") %>%
# filter(!is.na(ABSTRACT)) %>%
# select("TITLE", "ABSTRACT", "KEYWORDS", "AUTHOR", "BIBTEXKEY")
#
# # Now import the TB data
# sars <- bib2df("sars.bib") %>%
# filter(!is.na(ABSTRACT)) %>%
# select("TITLE", "ABSTRACT", "KEYWORDS", "AUTHOR", "BIBTEXKEY")Assume we are only looking for COVID19 papers to include in our review. That means we will need to exclude all SARS papers published in 2003. I used a simple include/exclude decisions.
We will now create a new binary factor factor variable called “Include”. We will then assign 1 for all covid papers and 0 for all SARS papers. To make the decisions look more in real world setting, I excluded 40 COVID papers published in August 22/2020. This has nothing to do with the contents of the papers. I am arbitrarily excluding the papers to make it look like a real world title/abstract screening process rather than a random decision.
After that I merged the two data frames with a simple rbind() code. I had a problem rendering UTF-8 characters in my github page for this blog post. So I have instead read everything using bib2df and then from there I wrote them in xlsx file. After that I simply read my excel file in R and did the whole analysis using the excel file.
# Exclude all covid papers
# covid$Include <- 1 # coded them as included
#
# covexclude$Include <- 0 # excluded
#
# cov2003$Include <- 1 # included
# sars$Include <- 0 # excluded
#
# # Now merge the tw data frames
# covid_sars <- rbind(covid, covexclude, sars, cov2003) # combine
#
# write.xlsx(covid_sars, file = "covidsars.xlsx",
# sheetName = "covidsars", append = FALSE) Rows: 983
Columns: 7
$ ...1 <chr> "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", ~
$ title <chr> "Factors determining the diffusion of COVID-19 and ~
$ abstract <chr> "This study has two goals. The first is to explain ~
$ keywords <chr> "Air Pollutants,Air Pollution,Betacoronavirus,Citie~
$ author <chr> "Coccia, Mario", "Ataguba, Ochega A and Ataguba, Jo~
$ label <chr> "Coccia2020", "Ataguba2020", "Sigala2020", "Lechner~
$ Include <chr> "included", "included", "included", "included", "in~#of characters
covid_sars$abstract_length <- nchar(covid_sars$abstract)
summary(covid_sars$abstract_length) Min. 1st Qu. Median Mean 3rd Qu. Max.
11 812 1239 1244 1620 4259 Check number of included/excluded papers
included not included
506 464 # check the type of this variable and convert it to factor
typeof(covid_sars$Include) # it is double. We have to convert it to factor variable[1] "character"covid_sars$Include[covid_sars$Include=="1"]<-"included"
covid_sars$Include[covid_sars$Include=="0"]<-"not included"
table(covid_sars$Include) %>% prop.table() #51% excluded, 49% included
included not included
0.5216495 0.4783505 Split the data

Machine learning algorithms require our data to be split into training and testing. The training data will be used to train the model and the testing data sets will be used to make predictions by deploying the model developed using the training sets. There are different ways of splitting our data to training and testing split. You may use base R, Resample or Caret package to easily perform this task. Here, I will use my favorite R packager: the Caret package. We will use 70/30 split which means 70% of my data will be assigned to the training set and 30% the data will be used for test sets.
I will need to stratify my data split by my dependent variable. That means my train and test data will have exactly similar proportion for the outcome variable responses as the original data sets. That is 51% for excluded (coded as 0) and 49% for included (coded as 1). The data is nearly balanced. We don’t have the curse of class imbalance here, awesome!
library(caret)
set.seed(3456) # for reproducibility
trainIndex <- createDataPartition(covid_sars$Include, p = .7,
list = FALSE,
times = 1)
train <- covid_sars[ trainIndex,]
test <- covid_sars[-trainIndex,]
prop.table(table(covid_sars$Include)) # outcome proportion for th original data
included not included
0.5216495 0.4783505 prop.table(table(train$Include)) # outcome proportion for training data
included not included
0.5220588 0.4779412 prop.table(table(test$Include)) # outcome proportion for testing data
included not included
0.5206897 0.4793103 # Cool! They have exactly similar proportions with respect to the outcome variable. The nice part

library(text2vec)
get_matrix <- function(text) {
it <- itoken(text, progressbar = FALSE)
create_dtm(it, vectorizer = hash_vectorizer())
}
dtm_train = get_matrix(train$abstract)
dtm_test = get_matrix(test$abstract)# Create boosting model for binary classification (-> logistic loss)
# Other parameters are quite standard
library(xgboost) # I will use extreme gradient boosting algorithm for building the model. But, I will also try other algorithms in the future.
param <- list(max_depth = 10,
eta = 0.1,
objective = "binary:logistic",
eval_metric = "error",
nthread = 1) # I will set the paprametres nearly similarly as it was described in the example from the package description.
xgb_model <- xgb.train(
param,
xgb.DMatrix(dtm_train, label = train$Include=="included"),
nrounds = 50
)Use the model to predict the test set

library(caret)
predictions <- predict(xgb_model, dtm_test)
# prediction probabilities
predict <- ifelse(predictions > 0.5, "included", "not included") # assign prediction probabilities greater than 0.5 as included and less than 0.5 as not included
confusionMatrix(as.factor(predict), as.factor(test$Include))Confusion Matrix and Statistics
Reference
Prediction included not included
included 143 9
not included 8 130
Accuracy : 0.9414
95% CI : (0.9078, 0.9655)
No Information Rate : 0.5207
P-Value [Acc > NIR] : <2e-16
Kappa : 0.8825
Mcnemar's Test P-Value : 1
Sensitivity : 0.9470
Specificity : 0.9353
Pos Pred Value : 0.9408
Neg Pred Value : 0.9420
Prevalence : 0.5207
Detection Rate : 0.4931
Detection Prevalence : 0.5241
Balanced Accuracy : 0.9411
'Positive' Class : included
It resulted 93.5% accuracy. In real world setting this may not happen because we will work on highly related titles and abstracts. My experiment brings two somehow related documents (SARS and covid19). ALthough we are explcitly looking for covid papers, I assigned some of the covid papers to be excluded just to add some confusion.
Let’s pick two abstracts(Abstract #89 and #271) and see what are the most important terms of the abstract that xgboost used for its predictions. We will use lime package to explain the predictions
Abstract number 89
We need to use lime:: to avoid conflicts with dplyrpackage
explanation89[, 2:10]# A tibble: 7 x 9
case label label~1 model~2 model~3 model~4 feature featu~5 featur~6
<int> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <dbl>
1 1 0 0.950 0.962 0.989 0.951 by by -0.0135
2 1 0 0.950 0.962 0.989 0.951 and and -0.00645
3 1 0 0.950 0.962 0.989 0.951 of of -0.00592
4 1 0 0.950 0.962 0.989 0.951 is is -0.00551
5 1 0 0.950 0.962 0.989 0.951 their their -0.00281
6 1 0 0.950 0.962 0.989 0.951 are are -0.00204
7 1 0 0.950 0.962 0.989 0.951 to to -0.00194
# ... with abbreviated variable names 1: label_prob, 2: model_r2,
# 3: model_intercept, 4: model_prediction, 5: feature_value,
# 6: feature_weightlime::plot_features(explanation89)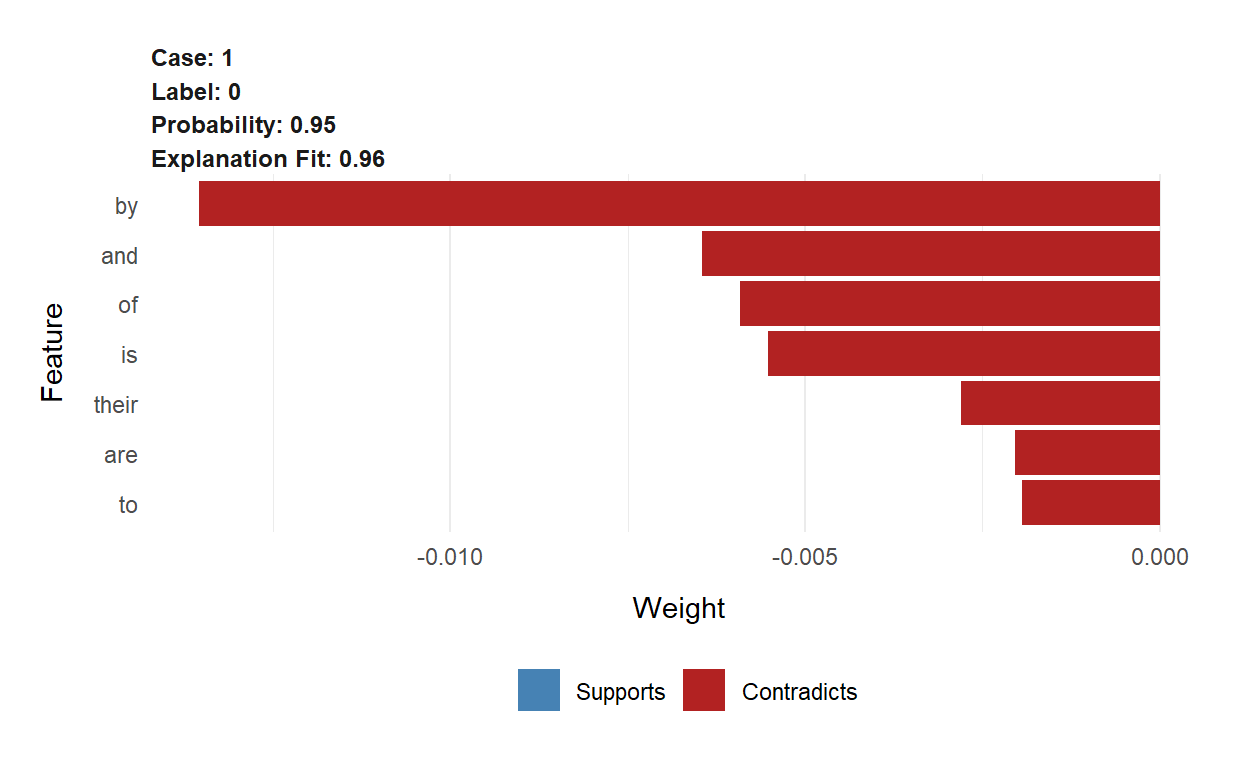
The word sars is most important word that xgb model used to predict the exclusion of this this abstract.
lime::plot_text_explanations(explanation89)Abstract 283
explanation[, 2:10]# A tibble: 7 x 9
case label label~1 model~2 model~3 model~4 feature featu~5 featur~6
<int> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <dbl>
1 1 1 0.935 0.997 -0.0123 0.931 corona corona 0.848
2 1 1 0.935 0.997 -0.0123 0.931 of of 0.0416
3 1 1 0.935 0.997 -0.0123 0.931 and and 0.0250
4 1 1 0.935 0.997 -0.0123 0.931 is is 0.0193
5 1 1 0.935 0.997 -0.0123 0.931 an an 0.00880
6 1 1 0.935 0.997 -0.0123 0.931 total total -0.00763
7 1 1 0.935 0.997 -0.0123 0.931 were were 0.00890
# ... with abbreviated variable names 1: label_prob, 2: model_r2,
# 3: model_intercept, 4: model_prediction, 5: feature_value,
# 6: feature_weightplot_features(explanation)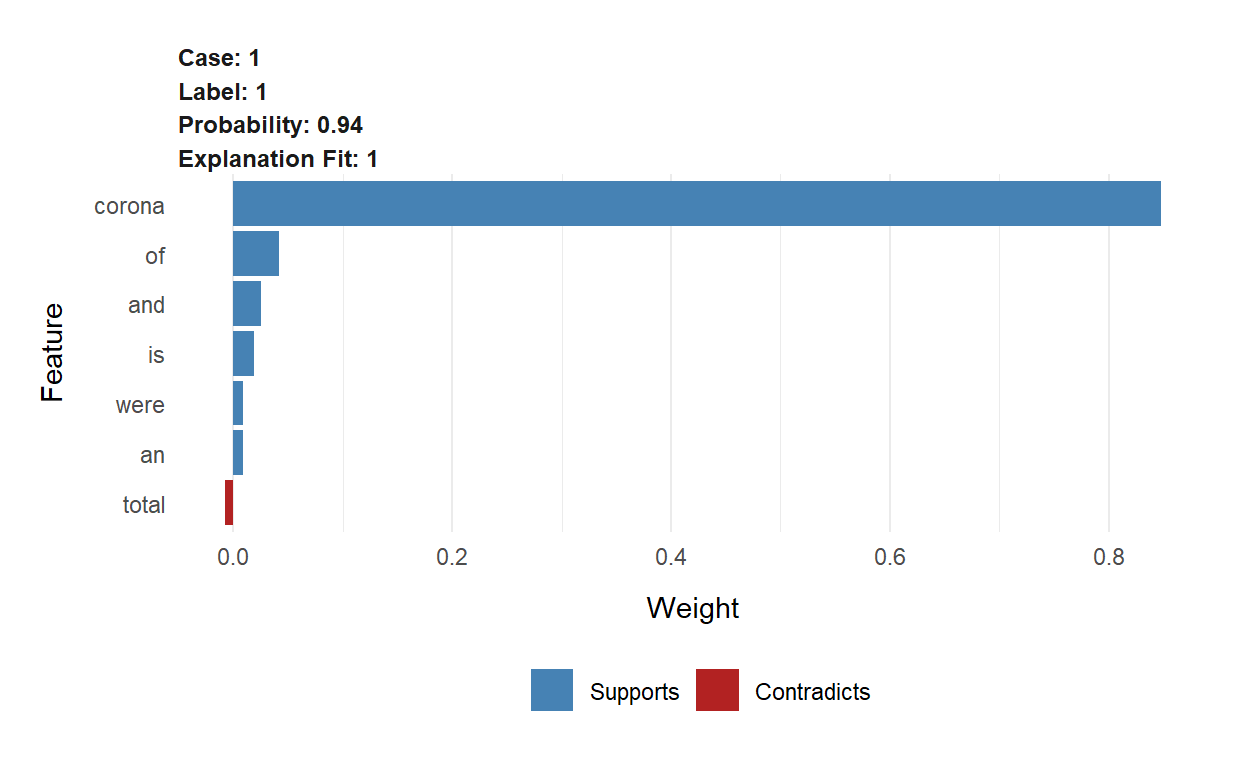
plot_text_explanations(explanation)The word corona is used for predicting “Include” with 87% prediction probability.
The above modelling is dirty.It didn’t use only the relevant words. I will use quanteda package to remove all irrelavnt words.
Create corpus
names(train) [1] "...1" "title" "abstract"
[4] "keywords" "author" "label"
[7] "Include" "abstract_length"train_data <- train[, 6] # I need only some of my variables: title, include, and label variable I don't need the rest of the variables for now. The label variable helps me to identify the papers it is written like Authoryyyy. I will use it to attach as a document identifier.
# Now build the corpus using abstracts of the papers
train_corpus <- corpus(train$abstract,
docvars = data.frame(abstract_label = names(train_data))) # I added the docvars to save the additional variables other than the abstractSimilarly for the test set
names(test) [1] "...1" "title" "abstract"
[4] "keywords" "author" "label"
[7] "Include" "abstract_length"Add document identifier for both test and training set data
Corpus consisting of 680 documents and 1 docvar.
Ataguba2020.1 :
"The coronavirus disease 2019 (COVID-19) pandemic has affecte..."
Sigala2020.1 :
"The paper aims to critically review past and emerging litera..."
Lechner2020.1 :
"Amidst the coronavirus pandemic, universities across the cou..."
VanDorp2020.1 :
"SARS-CoV-2 is a SARS-like coronavirus of likely zoonotic ori..."
Barilla2020.1 :
": ACE2 receptor has a broad expression pattern in the cellul..."
Zhang2020d.1 :
"The nucleocapsid protein is significant in the formation of ..."
[ reached max_ndoc ... 674 more documents ]Attach the document identifier also for the test set
Corpus consisting of 290 documents.
Coccia2020.1 :
"This study has two goals. The first is to explain the geo-en..."
Cagliani2020.1 :
"In December 2019, a novel human-infecting coronavirus (SARS-..."
Okba2020.1 :
"Middle East respiratory syndrome coronavirus (MERS-CoV) is a..."
Donthu2020.1 :
"The COVID-19 outbreak is a sharp reminder that pandemics, li..."
Wister2020.1 :
"The COVID-19 global crisis is reshaping Canadian society in ..."
Acter2020.1 :
"According to data compiled by researchers at Johns Hopkins U..."
[ reached max_ndoc ... 284 more documents ]Tokenize
I will create tokens and then later document feature matrix for both train and test abstract copuses. We do the same tokenization process as we did in my previous blog post. We will remove numbers, remove punctuation, or remove a customized list of stop words
custom_stop_words <- c("background", "introduction","aims", "objectives", "materials", "methods", "results", "conclusions","textless", "study")
train_tokens <- tokens(train_corpus, remove_punct = TRUE,
remove_numbers = TRUE)
train_tokens <- tokens_select(train_tokens, pattern = stopwords('en'), selection = 'remove') # remove irrelevant words
train_tokens <- tokens_select(train_tokens, pattern = custom_stop_words, selection = 'remove') # remove customized list of stop wordsI do the same for the test abstract corpuses
test_tokens <- tokens(test_corpus, remove_punct = TRUE,
remove_numbers = TRUE)
test_tokens <- tokens_select(test_tokens, pattern = stopwords('en'), selection = 'remove') # remove irrelevant words
test_tokens <- tokens_select(test_tokens, pattern = custom_stop_words, selection = 'remove') # remove customized list of stop wordsConstruct document feature matrix for both train and test abstract tokens
Have a quick look of the two document feature matrices
head(train_dfmat)Document-feature matrix of: 6 documents, 11,352 features (99.14% sparse) and 1 docvar.
features
docs coronavirus disease covid-19 pandemic affected many
Ataguba2020.1 2 2 6 3 1 7
Sigala2020.1 0 0 4 1 0 0
Lechner2020.1 2 0 0 2 0 0
VanDorp2020.1 1 0 1 1 0 0
Barilla2020.1 1 1 2 1 0 1
Zhang2020d.1 1 0 1 0 0 0
features
docs countries increasing morbidity mortality
Ataguba2020.1 7 1 2 1
Sigala2020.1 0 0 0 0
Lechner2020.1 0 0 0 0
VanDorp2020.1 1 0 0 0
Barilla2020.1 0 0 0 0
Zhang2020d.1 0 0 0 0
[ reached max_nfeat ... 11,342 more features ]head(test_dfmat)Document-feature matrix of: 6 documents, 6,869 features (98.40% sparse) and 0 docvars.
features
docs two goals first explain geo-environmental
Coccia2020.1 1 1 1 1 1
Cagliani2020.1 0 0 0 0 0
Okba2020.1 0 0 0 0 0
Donthu2020.1 0 0 0 0 0
Wister2020.1 0 0 0 0 0
Acter2020.1 1 0 0 0 0
features
docs determinants accelerated diffusion covid-19
Coccia2020.1 1 3 3 9
Cagliani2020.1 0 0 0 0
Okba2020.1 0 0 0 0
Donthu2020.1 0 0 0 1
Wister2020.1 0 0 0 4
Acter2020.1 0 0 0 1
features
docs generating
Coccia2020.1 1
Cagliani2020.1 0
Okba2020.1 0
Donthu2020.1 0
Wister2020.1 0
Acter2020.1 0
[ reached max_nfeat ... 6,859 more features ]dim(train_dfmat) # 646 abstracts 11191 features/terms[1] 680 11352dim(test_dfmat) # 276 abstracts 6668 features/terms[1] 290 6869# Or simply pass the dfm object in ndoc() or nfeat() functions
ndoc(train_dfmat)[1] 680nfeat(train_dfmat)[1] 11352ndoc(test_dfmat)[1] 290nfeat(test_dfmat)[1] 6869Vizualize the test and train document feature matrices
"When you visualize, then you materialize." Denis Waitley
Vizualizing the data is very importnat. Let’s see how the wordclouds look for train and test abstracts.
library(quanteda.textplots)
library(RColorBrewer)
pal <- brewer.pal(5, "Dark2")
textplot_wordcloud(train_dfmat, min_count = 40,max_words = 400,
color = pal)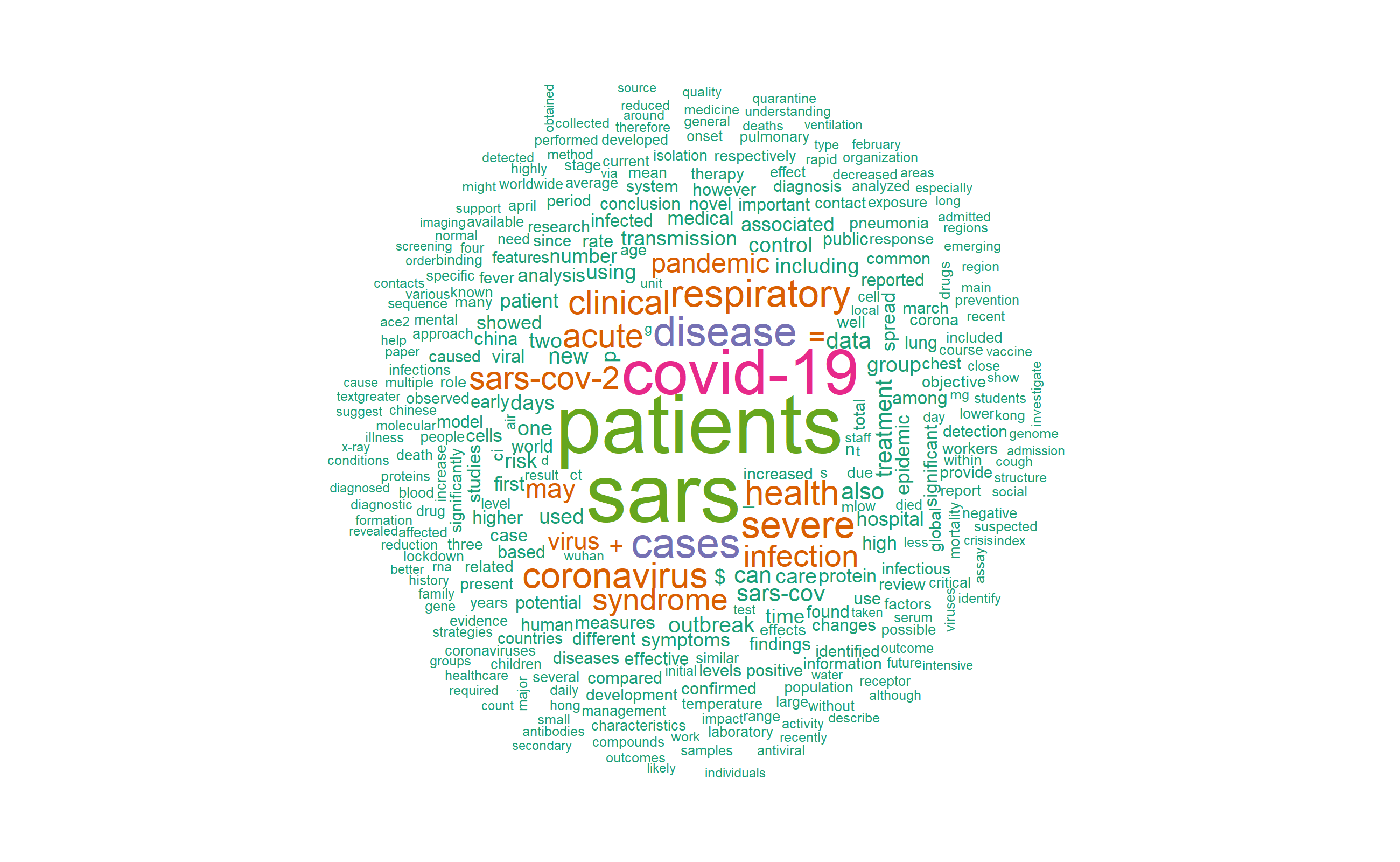
Similarly, for the test_dfmat
library(quanteda.textplots)
textplot_wordcloud(test_dfmat, min_count = 20,max_words = 400,
color = pal)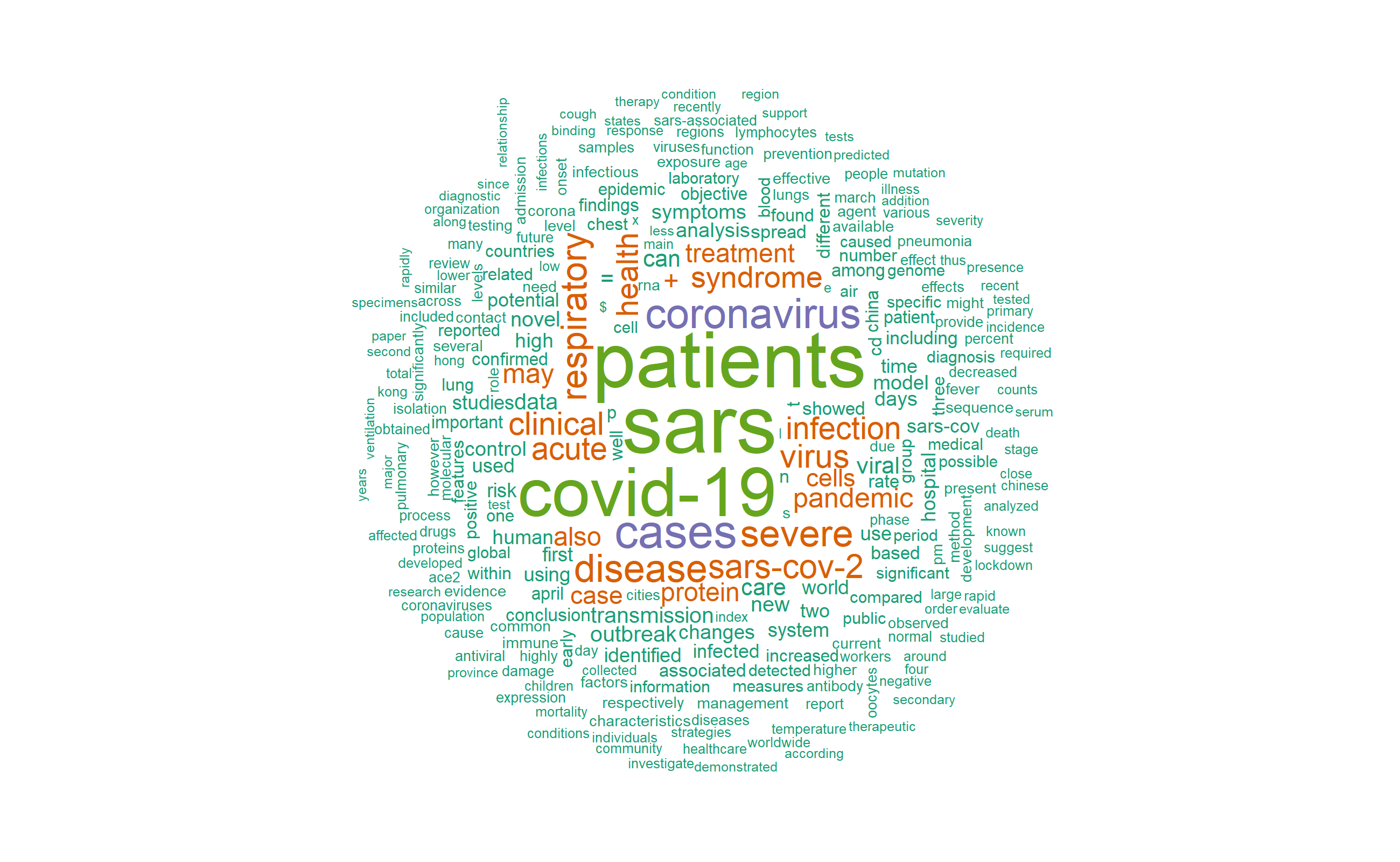
Both plots of the test and train data are comparable.
Prediction using Naive Bayes model
I need the following packages
naive_bayes <- textmodel_nb(train_dfmat,train$Include)
summary(naive_bayes)
Call:
textmodel_nb.dfm(x = train_dfmat, y = train$Include)
Class Priors:
(showing first 2 elements)
included not included
0.5 0.5
Estimated Feature Scores:
coronavirus disease covid-19 pandemic affected
included 0.003960 0.004630 0.0138695 0.0043808 0.0005356
not included 0.003552 0.004461 0.0006497 0.0004331 0.0006281
many countries increasing morbidity mortality
included 0.0008609 0.0011478 0.0005165 0.0002104 0.0006887
not included 0.0007797 0.0005847 0.0001299 0.0001083 0.0007797
interestingly actions policies adopted linked
included 9.565e-05 1.530e-04 2.678e-04 1.530e-04 0.0002487
not included 4.331e-05 8.663e-05 2.166e-05 2.166e-05 0.0001733
social determinants health sdh critical
included 0.0008035 7.652e-05 0.003539 1.148e-04 0.0007652
not included 0.0001949 1.083e-04 0.003617 2.166e-05 0.0004765
inequalities directly within sector distancing
included 3.826e-05 0.0002296 0.0005739 1.722e-04 2.870e-04
not included 2.166e-05 0.0001733 0.0009529 6.497e-05 6.497e-05
good hygiene avoiding large gatherings
included 0.0002487 0.0001722 1.339e-04 0.0006887 3.826e-05
not included 0.0002166 0.0001299 2.166e-05 0.0005847 2.166e-05Since we have already our model, we can use it for predicting the test sets. Unfortunately, the features in test_dfmat which are also in train_dfmat. Quanteda package has one really nice function called dfm_match() to select only features of the testing set that also occur in the training set.
actual_class <- test$Include
predicted_class <- predict(naive_bayes, newdata = matched_dfmat)
tab_class <- table(predicted_class, actual_class )
tab_class actual_class
predicted_class included not included
included 134 13
not included 17 126confusionMatrix(tab_class, mode = "everything")Confusion Matrix and Statistics
actual_class
predicted_class included not included
included 134 13
not included 17 126
Accuracy : 0.8966
95% CI : (0.8556, 0.9291)
No Information Rate : 0.5207
P-Value [Acc > NIR] : <2e-16
Kappa : 0.793
Mcnemar's Test P-Value : 0.5839
Sensitivity : 0.8874
Specificity : 0.9065
Pos Pred Value : 0.9116
Neg Pred Value : 0.8811
Precision : 0.9116
Recall : 0.8874
F1 : 0.8993
Prevalence : 0.5207
Detection Rate : 0.4621
Detection Prevalence : 0.5069
Balanced Accuracy : 0.8969
'Positive' Class : included
Our models predicted the test data set with 89.5% accuracy. This is wonderful! The other model performance parameters are also very good. How about Support Vector Machines?
train_svm <- textmodel_svm(train_dfmat,train$Include, weight="uniform") # There are three weighting options. I don't have problem of class imbalance, let me just use the default "uniform"Predict the test set using SVM model
Actual <- test$Include
predicted_class_svm <- predict(train_svm, newdata = matched_dfmat)
tab_class_svm <- table(predicted_class_svm, Actual )
tab_class_svm Actual
predicted_class_svm included not included
included 143 11
not included 8 128Now the confusion matrix
confusionMatrix(tab_class_svm, mode = "everything")Confusion Matrix and Statistics
Actual
predicted_class_svm included not included
included 143 11
not included 8 128
Accuracy : 0.9345
95% CI : (0.8996, 0.9601)
No Information Rate : 0.5207
P-Value [Acc > NIR] : <2e-16
Kappa : 0.8686
Mcnemar's Test P-Value : 0.6464
Sensitivity : 0.9470
Specificity : 0.9209
Pos Pred Value : 0.9286
Neg Pred Value : 0.9412
Precision : 0.9286
Recall : 0.9470
F1 : 0.9377
Prevalence : 0.5207
Detection Rate : 0.4931
Detection Prevalence : 0.5310
Balanced Accuracy : 0.9339
'Positive' Class : included
SVM prediction is quite remarkable. Almost 92.5% accurate prediction. This is cool. Look at the other performance measures: sensitivity, specificity, PVP, NPV, recall, precision. They are all more than 90%!
One limitation of implementing these models using quanteda.textmodels is we cannot benefit the great advantages of lime package, we cannot use lime to explain our naive_bayes model locally (within abstracts) as we did it our prediction using XGB because lime currently doesn’t support quanteda.textmodels package. Currently lime package only explains models developed using mlr, xgboost, h2o, keras, or MASSpackages.
Final remarks
I have tried three different models and the level of accuracy has improved through my model choices. I see lots of beautiful things that we can take advantage of NLP for systematic reviews. However, the process is quite complex, computationally expensive and we don’t know which model works best unless we experiment several models with broad range of model parameters. I can see its tremendous potential even after such a tiny scratch on its surface. We don’t know how much I will gain in improving the prediction accuracies if I process my abstracts using *tf-idf*, n-grams, the mighty cross-validation processes, and redo my analysis with several models including deep learning, etc.
Next stop
Visualizing odds ratios/risk ratios in forest plots. See you!

Contact
If you have enjoyed reading this blog post, consider subscribing for upcoming posts.